Chat with my blog: A RAG based chatbot that talks about me and my blog !
Large Language Models (LLMs) have revolutionized how we interact with information. They are quickly augmenting traditional search based methods for interacting with the Web, providing more natural sounding responses. My blog has been steadilty growing in size, which makes it a necessity to have a way to search and extract information from it.
This gave me the perfect opportunity to implement a personal chatbot that can answer questions about my blog and myself ! In this blog I will discuss about the core mechanisms powering my chatbot hosted at https://chat.jayeshdev.com, as well some brief discussion about the actual implementation.
Retreival Augmented Generation
Large Language Models (LLMs) excel at generating text based on a given input. However, they face limitations in adapting to real-world scenarios because of the following reasons:
- Fixed Knowledge: The knowledge of the model is limited to the data it was trained on. Hence asking questions outside of the training domain or “cut-off” date can lead to inaccurate answers.
- Lack of Citations: These models generate answers without referencing specific parts of the dataset they draw from, making it challenging to attribute sources.
- Costly Training: Training LLMs is a resource-intensive process, making frequent updates for domain-specific use cases economically impractical.
To address these challenges, Lewis et al[1] introduced Retrieval-Augmented Generation (RAG), which enables LLMs to access external data during inference. This approach injects relevant knowledge into the model, leading to more grounded and accurate responses.
A Question Answering RAG System with history
A simple Question Answering RAG system has the following modules:
- Parser + Chunker: This module parses and breaks down external text data into smaller, digestible chunks.
- Embedding Model: It generates vector representations from these text chunks.
- Vector Database: This stores the generated embeddings, facilitating efficient retrieval based on vector similarity.
- Generation Model: The base LLM responsible for generating responses.
Setting up a RAG system involves ingesting external knowledge and preparing it for use:
- Parse external text data and chunk it for embedding.
- Convert these chunks into vectors and store the text, vector pairs in the Vector Database.
Once setup, users can query the system for answers. When a user query is received, the system follows these steps:
- Embed the user query into a query vector.
- Retrieve relevant text chunks from the database based on vectors similar to the query vector.
- Generate a response using a prompt derived from the user query and retrieved text chunks.
Q&A with chat history
While the above setup works well for independent queries, what if we want our chatbot to reference previous conversations alongside external knowledge?
To accommodate this, we can enhance the querying stage to incorporate chat history:
- Use the generation model to generate a standalone query that incorporates both the user query and the chat history.
- Follow the standard querying flow to retrieve and generate responses.
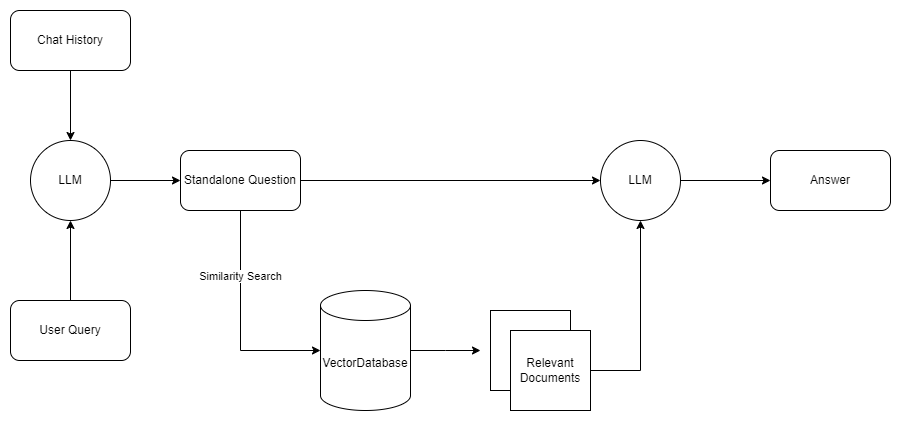
Source: "What Is Retrieval-Augmented Generation, aka RAG?", Nvidia, 2023
Personal Chatbot Implementation
My personal implementation of RAG-based Question Answering chatbot is hosted at https://chat.jayeshdev.com with the source code available at my rag-chatbot github repository.
Rather than starting from scratch, I built the chatbot on top of the excellent chat-langchain github repo.
The repo contains codebase of the chatbot LangChain has built for it’s documentation and deployed at chat.langchain.com. They have used LangChain, FastAPI and NextJS to build the chatbot, and have predefined scripts for ingestion and querying logic.
My application is built using the following technologies:
- Backend:
- Frontend:
- NextJS & Chakra UI for the UI
- LangchainJS for interacting with backend APIs
- Deployment:
- Docker for containerization and multi stage builds
- Docker Compose for orchestrating multi-container applications
I made the following modifications to the original code:
- Backend:
- Refactor to use self hosted Chroma Vector Database (with security) instead of Weaviate Cloud.
- use Together AI for embedding (msmarco-bert-base-dot-v5) and answer generation (Mixtral-Instruct-v0.1).
- Add support for parsing using Unstructured IO during ingestion.
- An improved chain that generates better standalone questions and incorporates summary of chat history.
- Refactoring to improve modularity and maintainability.
- Improved prompts with step-by-step instructions and few-shot examples.
- Add support for using Open Source Langfuse instead of Langsmith for monitoring.
- Frontend:
- Removed Langsmith integration
- Modified the example prompts and page contents
- Added footer element for links to my social
- Deployment:
- Added Dockerfiles with multi stage building for backend and frontend to keep deployment lightweight.
Let’s have a look at some of the key concepts of my implementation:
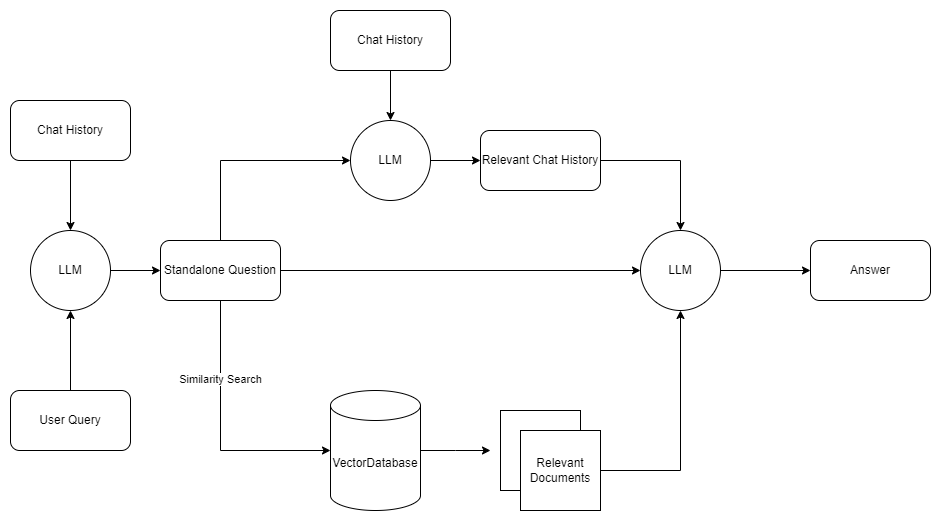
Improved Chain
For my usecase, I wanted the system to base it’s answer not only on the retreived documents but also on any relevant chat history. This enables the system to answer self referential questions by the user (For e.g “What is my name?”) later down the conversation.
To achieve this, I added an additonal “Relevant Chat History” extraction step that we perform after the standalone question generation. This extracts messages from the conversation history that are relevant to answering the standalone question. Then the final prompt to the LLM incorporates both retreived documents as well as relevant chat history to generate answers.
I also use different models for embedding (msmarco-bert-base-dot-v5) vs answer generation (Mixtral-Instruct-v0.1).
Improved prompts
After constructing the chain, I conducted testing. During this process, I observed some discrepancies in the expected behavior of the LLM, particularly in the generation phases of “Standalone Question” and “Relevant Chat History”. To ameliorate this, I created new prompts that include step-by-step instructions along with relevant examples. Upon integration of these improved prompts, the system deviations went down significantly.
LangFuse Integration
LangFuse is an open source LLM monitoring framework, that allows users to trace the entire prompt chain. This allows me to inspect the following data:
- What are the inputs and outputs of my system and how much time it took to run ?
- What standalone questions were crafted based on history ?
- What relevant history was extracted from a conversation ?
- What documents were found relevant to a question using vector similarity search ?
Integrating Langfuse was slightly tricky, as although it comes with built in support for Langchain, there is no documentation on integrating it with LangServe. The trick I used was to create a function that modifies Langchain config every request to add the LangFuse callback, as show below:
# Create a Langfuse handler
langfuse_handler = CallbackHandler(
secret_key = os.environ.get("LANGFUSE_SECRET_KEY", "not_provided"),
public_key = os.environ.get("LANGFUSE_PUBLIC_KEY", "not_provided"),
host = "https://cloud.langfuse.com"
)
# Create a function that adds the LangFuse callback to config
def add_langfuse_callback(config, request):
config.update({"callbacks": [langfuse_handler]})
return config
# While calling the LangServe add_routes method, pass the add_langfuse_callback function as a per requestion config modifier.
add_routes(
app,
answer_chain,
path="/chat",
input_type=ChatRequest,
config_keys=["metadata", "configurable", "tags"],
per_req_config_modifier = add_langfuse_callback
)
Conclusion
In this blog post I discussed about Retrieval Augmented Generation (RAG) systems, and how can they be constructed. Finally, I briefly discussed the implementation details of the chatbot I built for my blog, complete with the code available on the rag-chatbot github repository.